布隆过滤器
什么是布隆过滤器?
本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器原理
布隆过滤器内部维护一个bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3….)计算不同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。 需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
下面以网址为例来进行说明, 例如布隆过滤器的初始情况如下图所示: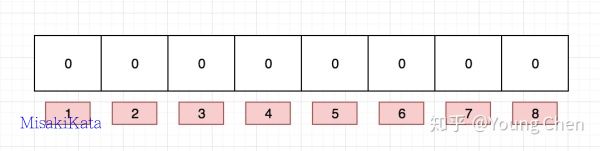
现在我们需要往布隆过滤里中插入baidu这个url,经过3个哈希函数的计算,hash值分别为1,4,7,那么我们就需要对布隆过滤器的对应的bit位置1, 就如图下所示:
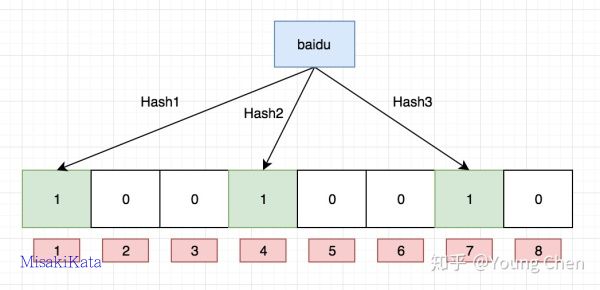
接下来,需要继续往布隆过滤器中添加tencent这个url,然后它计算出来的hash值分别3,4,8,继续往对应的bit位置1。这里就需要注意一个点, 上面两个url最后计算出来的hash值都有4,这个现象也是布隆不能确认某个元素一定存在的原因,最后如下图所示:
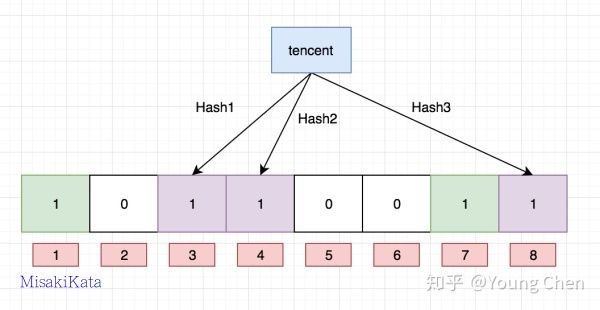
布隆过滤器的查询也很简单,例如我们需要查找python,只需要计算出它的hash值, 如果该值为2,4,7,那么因为对应bit位上的数据有一个不为1, 那么一定可以断言python不存在,但是如果它计算的hash值是1,3,7,那么就只能判断出python可能存在,这个例子就可以看出来, 我们没有存入python,但是由于其他key存储的时候返回的hash值正好将python计算出来的hash值对应的bit位占用了,这样就不能准确地判断出python是否存在。
因此, 随着添加的值越来越多, 被占的bit位越来越多, 这时候误判的可能性就开始变高,如果布隆过滤器所有bit位都被置为1的话,那么所有key都有可能存在, 这时候布隆过滤器也就失去了过滤的功能。至此,选择一个合适的过滤器长度就显得非常重要。
从上面布隆过滤器的实现原理可以看出,它不支持删除, 一旦将某个key对应的bit位置0,可能会导致同样bit位的其他key的存在性判断错误。
如何在python中使用布隆过滤器
先去这个网站下载
bitarray这个依赖https://www.lfd.uci.edu/~gohlke/pythonlibs/#bitarray直接安装会报错
error: Microsoft Visual C++ 14.0 is required. Get it with "Build Tools for Visual Studio": https://visualstudio.microsoft.com/downloads/安装
wheel文件, 防止我们主动安装报这样的错误pip3 install bitarray-1.1.0-cp36-cp36m-win_amd64.whlpip3 install pybloom_live
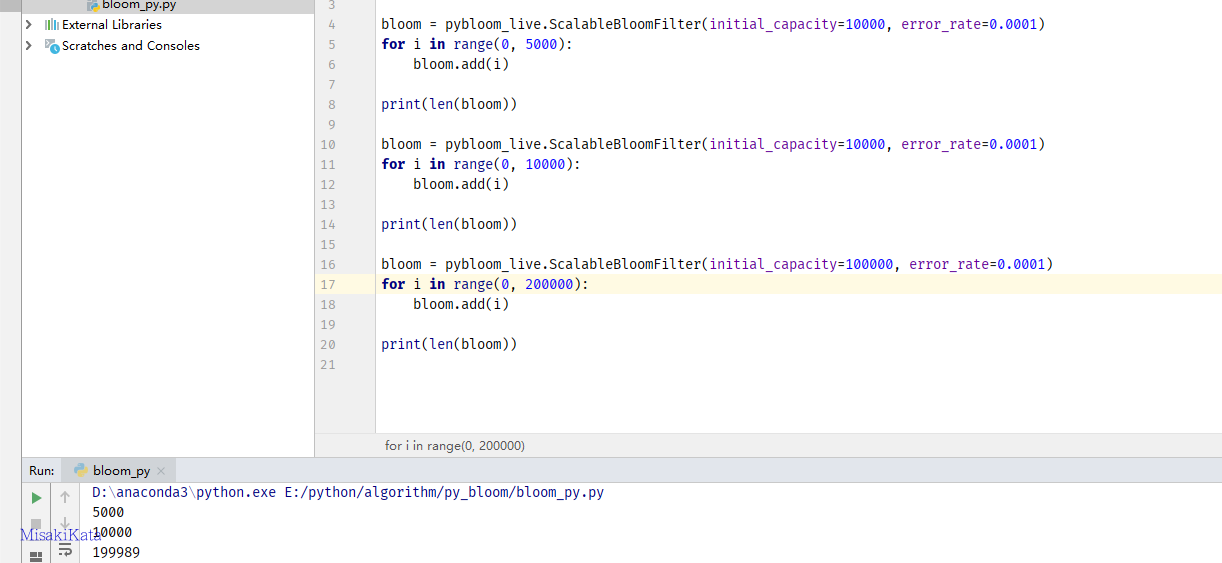
该模块包含两个类实现布隆过滤器功能。BloomFilter 是定容。ScalableBloomFilter 可以自动扩容
import pybloom_live
bloom = pybloom_live.BloomFilter(capacity=10000) #定容一万
for i in range(0, 10001):
bloom.add(i)
print(len(bloom))
bloom.add(10002)
bloom.add(10003)
print(len(bloom))当超过一万时,会提示一个越界提示,IndexError: BloomFilter is at capacity。看起来好像不如自动扩容的好用。对比一下定容数量和扩容数量的差别。
误判率默认是设置为千分之一,按照默认的误判率来做对比,当数量在定容内,误判率远低于设置的误判率,但数量超过定容时,准确度基本按照设置的误判率来控制。
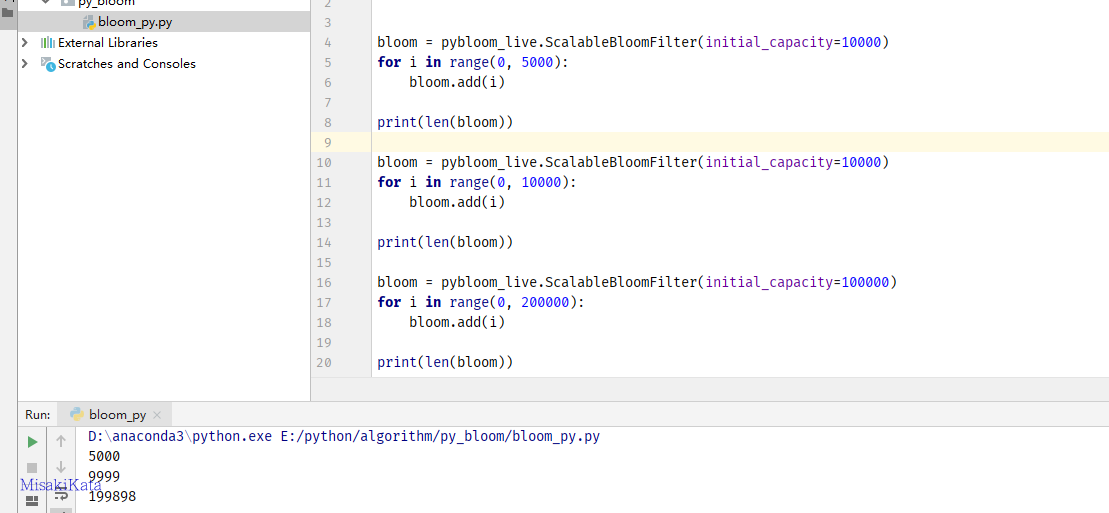
如果需要自动扩容来处理不确定的数量差别,可以使用error_rate来控制误判率。
redis 使用
docker拉取redis环境
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest创建一个新过滤器
106.54.181.x:6379> bf.reserve newbloom 0.001 10000
OK添加一个新的值,存在返回0,不存在会返回1
106.54.181.x:6379> bf.add name 1111
(integer) 1
106.54.181.x:6379> bf.add name 1111
(integer) 0判断值是否存在,不存在返回0,存在返回1。
106.54.181.x:6379> bf.exists name 1111
(integer) 1
106.54.181.x:6379> bf.exists name 2222
(integer) 0添加多个新的值
106.54.181.187:6379> bf.madd name 2222 3333
1) (integer) 1
2) (integer) 1使用https://github.com/RedisBloom/redisbloom-py编写一个简单的添加脚本
from redisbloom.client import Client
class _redis_bloom(object):
def __init__(self, size, error=0.001, key='name'):
self.size = size
self.error = error
self.key = key
self.rb = Client(host='106.54.181.x', port=6379)
self.rb.bfCreate(self.size, self.error, self.key)
self.rb.delete(key)
def insert(self, name):
if self.rb.bfExists(self.key, name) == 0:
self.rb.bfAdd(self.key, name)
return True
else:
return False
rd = _redis_bloom(size=10000)
for i in range(0, 5000):
rd.insert(i)
布谷鸟过滤器
布谷鸟过滤器
布谷过滤器(cuckoo fliter),这个名字来源于更早发表的布谷散列(cuckoo hash),为了解决布隆过滤器不能删除的问题而出现。
采用一部分示意图说明布谷散列
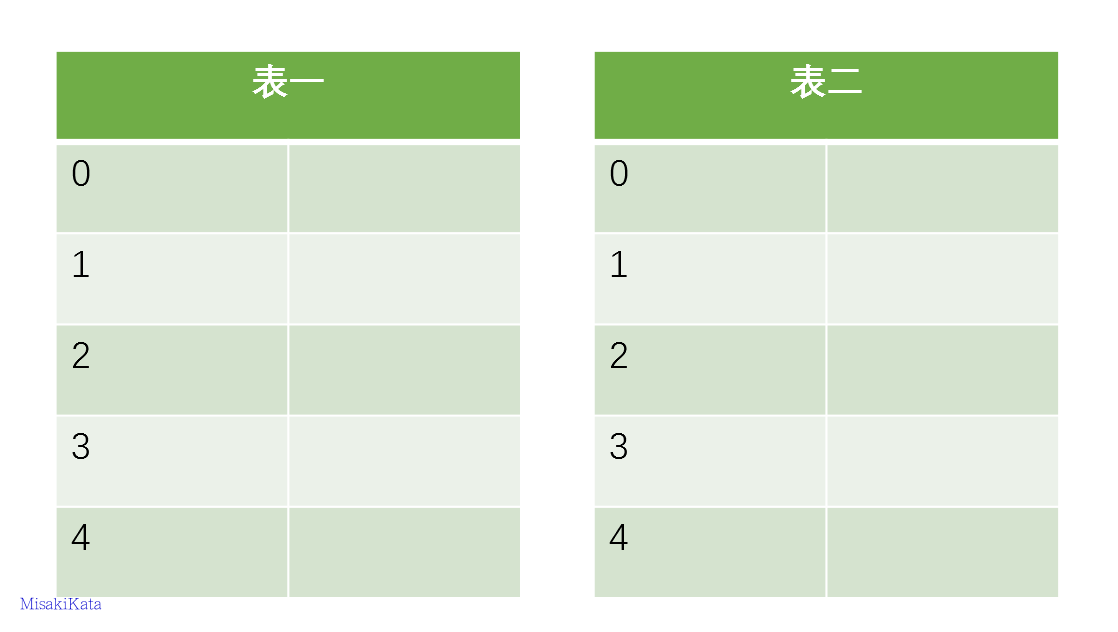
现在我们假设有一些项要存入散列表,其每个项都有其对应的两个位置,先插入第一项A
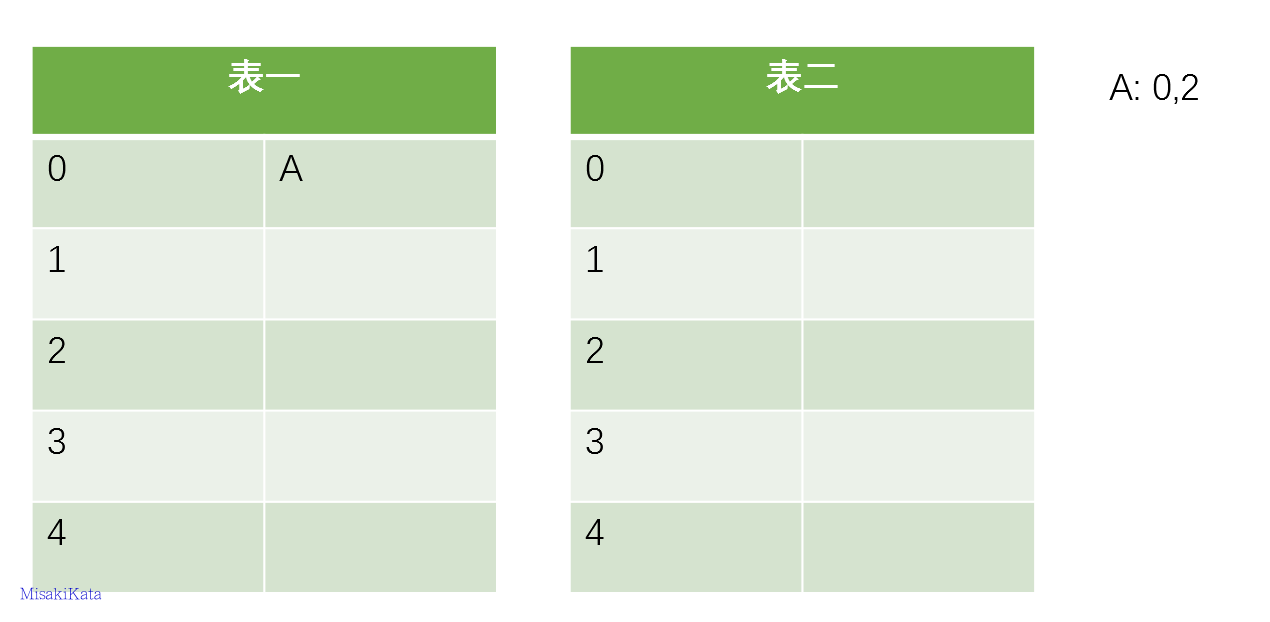
由于插入A的时候其两个候选位置(0,2)都没有占用,所以选择第一张表或者是第二张表都可以,我们在这里默认先选择第一张表,然后插入第二项B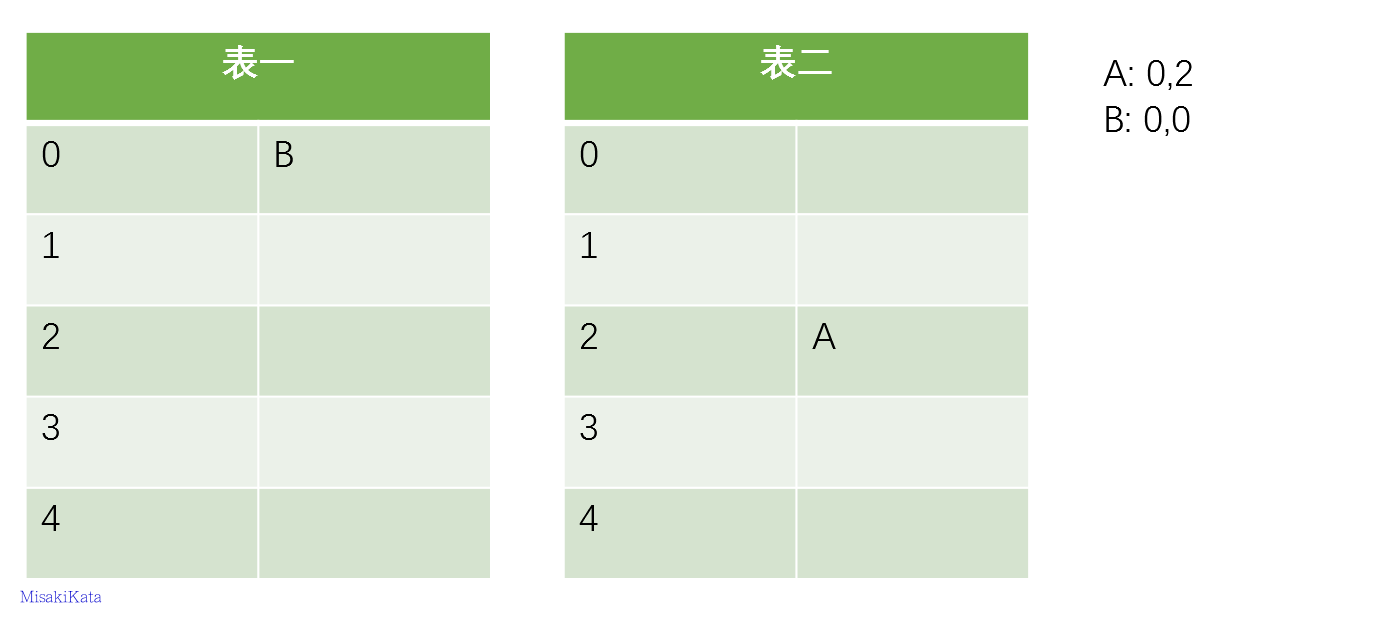
我们看到原来的A的位置被B占用,而A被“踢”到它的备选位置表二的2号位置上了,这就是当发生位置冲突时,布谷散列表的处理逻辑,后来的数据项将会把之前占用的项踢到另一个位置上。我们接下来插入第三项C
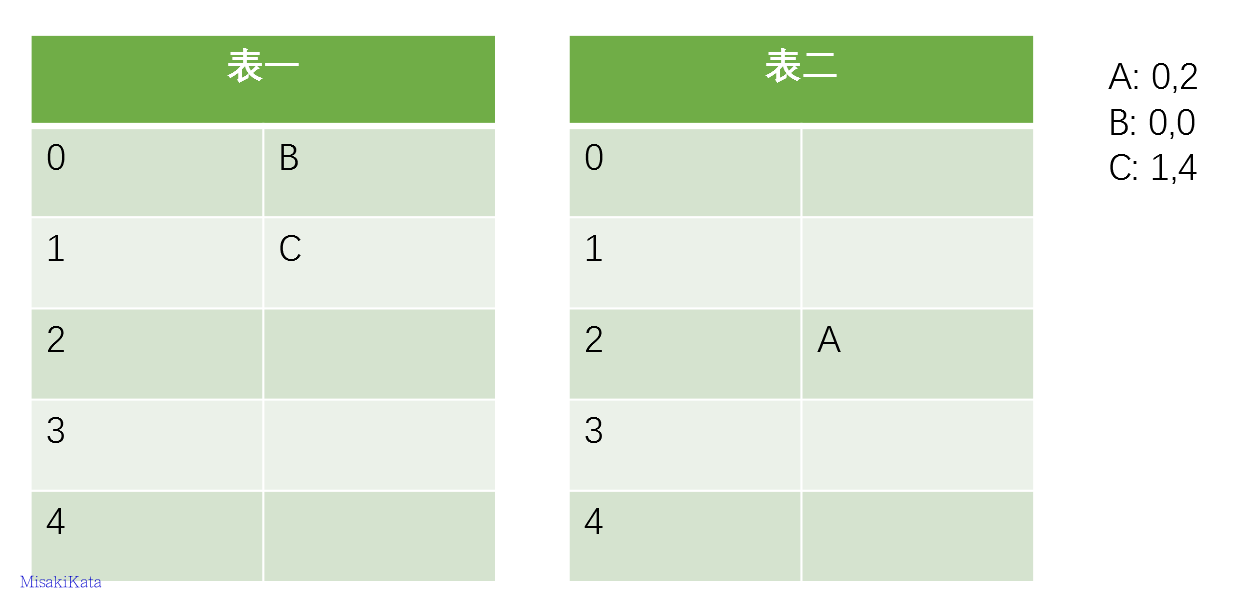
没有冲突,顺利搞定,接着插入D
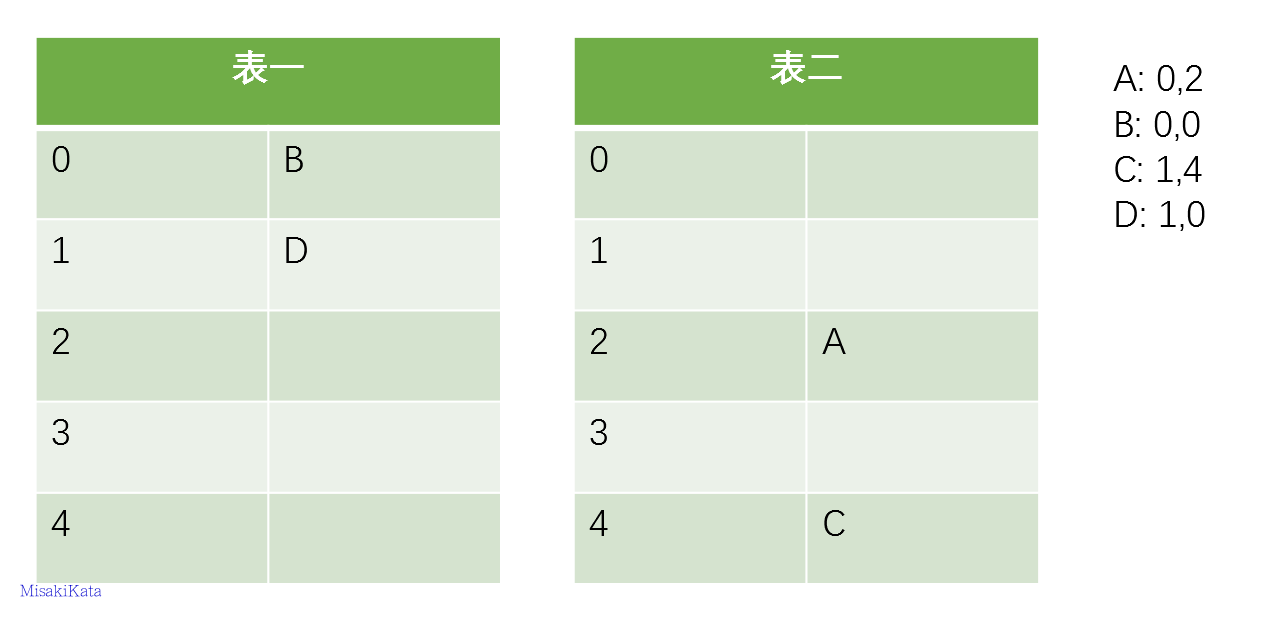
D成功的把C踢走了,其实看到这里读者应该在猜想,会不会有一种情况,即被踢走的数据的另一个备选位置也被占用了,这样怎么办?答案是继续踢,一个踢一个,直到大家都找到自己合适的归宿为止。
布谷鸟过滤器的问题
从上面看出来,布谷鸟过滤器会让数据不停的找自己的位置,这样就会达到一个循环,比如表一某个数踢走一个到表二,表二中的数又踢走一个表一,这样会不停的循环影响效率。所以这时候布谷鸟过滤器就有一个阈值,当超过这个阈值就会说明过滤器数组满了。需要扩容,而实际并不一定满。
因为上面只设置了两个巢,所以空间利用率比较低,可能也就百分之五十左右。这时候就需要改进算法, 比如不再设置两个巢,而是较多的巢来保证可以将循环降低。
随着布谷鸟过滤器的装满,插入将变得缓慢,因为需要踢走更多的物品。如果程序对插入时间很敏感,布谷鸟过滤器并不一定适合。
另外还有一个明显的问题就是,如果插入一个数据插入了多次,就会产生自己踢自己的结果,将导致几个位置上都是同一个数据,不止如此还会提早的达到数组阈值。导致空间利用率底下。也许可以使用一次查询来解决此问题。
但是删除的时候会出现一定概率的误删。因为不同的元素被 hash 到同一个位置的可能性还是很大的,而且指纹只有一个字节,256 种可能,同一个位置出现相同的指纹可能性也很大。如果两个元素的 hash 位置相同,指纹相同,那么这个插入检查会认为它们是相等的。
python实现布谷鸟过滤器
pip install cuckoopyfrom cuckoopy import CuckooFilter
ck = CuckooFilter(capacity=1000, bucket_size=4, fingerprint_size=1) #每个位置四个座位,指纹字节长度为1
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
ck.insert('hello')
print(ck.contains('hello'), ck.size)这种情况下,当插入同一个数据超过八次的时候,由于两个桶的八个座位都被一个数据占用,会出现循环踢的情况,超过阈值导致认为数据桶一件满了。
cuckoopy.exceptions.CuckooFilterFullException: Insert operation failed. Filter is full.所以在使用布谷鸟过滤器的时候,需要先进行一次查询,如果数据存在则不在进行插入。
from cuckoopy import CuckooFilter
ck = CuckooFilter(capacity=1000, bucket_size=4, fingerprint_size=1) #每个位置四个座位,指纹字节长度为1
ck.insert('hello')
if not ck.contains('hello'):
ck.insert('hello')
else:
print("数据重复!")
print(ck.contains('hello'), ck.size) #数据重复! True 1redis 使用
使用方式跟布隆过滤器基本一致,需要把bf改为cf即可
CF.RESERVE newCuckooFilter 1000 #新建一个过滤器
CF.ADD newCuckooFilter foo #增加一个值
CF.EXISTS newCuckooFilter foo #判断是否存在
CF.DEL newCuckooFilter foo #删除同样使用上面的脚本
from redisbloom.client import Client
class _redis_cuckoo(object):
def __init__(self, size, key='name'):
self.size = size
self.key = key
self.rb = Client(host='106.54.181.x', port=6379)
self.rb.cfCreate(self.key,self.size)
def insert(self, name):
if self.rb.cfExists(self.key, name) == 0:
self.rb.cfAdd(self.key, name)
return True
else:
return False
rd = _redis_cuckoo(size=10000)
for i in range(0, 5000):
rd.insert(i)令牌桶算法
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
实现代码:https://github.com/titan-web/rate-limit/blob/master/token_bucket/__init__.py
import time
from threading import RLock
__all__ = ("TokenBucket", )
class TokenBucket(object):
def __init__(self, capacity, fill_rate, is_lock=False):
"""
:param capacity: The total tokens in the bucket.
:param fill_rate: The rate in tokens/second that the bucket will be refilled
"""
self._capacity = float(capacity)
self._tokens = float(capacity)
self._fill_rate = float(fill_rate)
self._last_time = time.time()
self._is_lock = is_lock
self._lock = RLock()
def _get_cur_tokens(self):
if self._tokens < self._capacity:
now = time.time()
delta = self._fill_rate * (now - self._last_time) # 计算从上次发送到这次发送,新发放的令牌数量
self._tokens = min(self._capacity, self._tokens + delta) # 令牌数量不能超过桶的容量
self._last_time = now
return self._tokens
def get_cur_tokens(self):
if self._is_lock:
with self._lock:
return self._get_cur_tokens()
else:
return self._get_cur_tokens()
def _consume(self, tokens):
if tokens <= self.get_cur_tokens(): # 如果没有足够的令牌,则不能发送数据
self._tokens -= tokens
return True
return False
def consume(self, tokens): #发送数据需要的令牌
if self._is_lock:
with self._lock:
return self._consume(tokens)
else:
return self._consume(tokens)调用的方式是传入需要的令牌数,比如
tk = TokenBucket(capacity=10, fill_rate=10) #容量10,每秒10个令牌
while True:
if tk.consume(1):
print('1111')
else:
print('2222')
time.sleep(1)会显示如下:
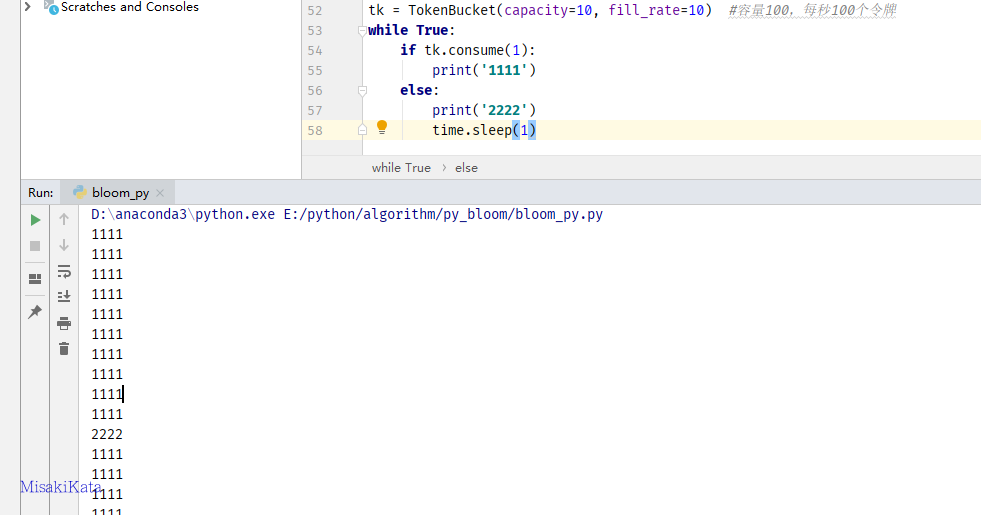
当桶内令牌又新增的时候会继续发送。
漏桶算法
漏桶算法(Leaky Bucket)它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。 在网络中,漏桶算法可以控制端口的流量输出速率,平滑网络上的突发流量,实现流量整形,从而为网络提供一个稳定的流量。
实现代码:https://github.com/titan-web/rate-limit/blob/master/leaky_bucket/__init__.py
from time import time, sleep
from threading import RLock
__all__ = ("LeakyBucket", )
class LeakyBucket(object):
def __init__(self, capacity, leak_rate, is_lock=False):
"""
:param capacity: The total tokens in the bucket.
:param leak_rate: The rate in tokens/second that the bucket leaks
"""
self._capacity = float(capacity)
self._used_tokens = 0
self._leak_rate = float(leak_rate)
self._last_time = time()
self._lock = RLock() if is_lock else None
def get_used_tokens(self):
if self._lock:
with self._lock:
return self._get_used_tokens()
else:
return self._get_used_tokens()
def _get_used_tokens(self):
now = time()
delta = self._leak_rate * (now - self._last_time) #间隔时间新泄露的漏桶令牌数
self._used_tokens = max(0, self._used_tokens - delta) #获取数不超过漏桶最大容量
return self._used_tokens
def _consume(self, tokens):
if tokens + self._get_used_tokens() <= self._capacity: #小于桶容量继续存储
self._used_tokens += tokens
self._last_time = time()
return True
return False
def consume(self, tokens): #发送数据需要的令牌
if self._lock:
with self._lock:
return self._consume(tokens)
else:
return self._consume(tokens)使用类似如上的方法调用
ck = LeakyBucket(capacity=20, leak_rate=5) #桶容量20,每秒泄露5
while True:
if ck.consume(1):
print('1111')
else:
print('2222')
sleep(1)结果首先把桶内的泄露完,此后每秒泄露五个。如果修改泄露数为30,这样结果任然是最多20个泄露。
参考文章:https://www.cnblogs.com/yscl/p/12003359.html
https://www.cnblogs.com/chuxiuhong/p/8215719.html